
ADMEデータによる予測モデリング
医薬品候補の2つに1つは有効性が不十分であるために臨床試験段階で失敗し、5つに2つは毒性が原因で失敗したことがあると言われています。*1 *2 規制当局や研究者は、薬理特性に加えて、吸収(Absorption)・分布(Distribution)・代謝(Metabolism)・排泄(Excretion)(ADME)試験が医薬品候補の成功に不可欠であることを認識しています。10年以上前から、製薬会社はリピンスキーの法則(Lipinski's rule of five)のようなルールベースのフィルターを使用して、望ましくないADMEプロファイルを回避してきました。さらに最近では、予測モデリングに頼るようになりました。
薬物のADMEプロファイルを評価するために予測モデルを使用します。そのため、データサイエンティストはアルゴリズムの試験をするための大量のADMEデータを必要とします。データ量は非常に重要ですが、データの多様性も重要です。データセットに含まれるユニークな化合物が多ければ多いほど、正確な予測ができる確率が高くなります。本稿では、ADMEデータにおける構造多様性の重要性を紹介し、GOSTARとChEMBLを比較して、予測モデルの精度向上に最も適したデータベースを確認します。徹底的な重複解析の結果、GOSTARデータの多様性はChEMBLデータの2倍から7倍であることがわかりました。
データの網羅性と量:正確な薬物動態の予測に必要不可欠
創薬・開発において、人体における薬剤候補の挙動を正確に予測することは非常に重要です。薬物動態額は一般に、 吸収・分布・代謝・排泄(ADME)の4つのカテゴリーに分類されます。計算科学者やデータサイエンティストは、人工知能(AI)や機械学習(ML)モデルを構築してADMEデータを分析し、医薬品候補の有効性と安全性を予測します。ターゲットとの相互作用が成功する確率が高く、副作用の可能性が低い候補は、医薬品開発プログラムを経て、臨床試験へと進みます。そのため、AI/MLモデルが薬物の挙動を正確に予測できることが極めて重要です。
不正確な予測は、多大な時間と費用の浪費を筆頭に、深刻な結果をもたらす可能性があります。しかし、モデルやアルゴリズムが不正確さの原因であることはほとんどありません。多くの場合、その原因はデータにあります。
データの品質を決定する重要な要因の1つは、そのセットに含まれるユニークな化合物の数です。
医薬品開発における正確なADME予測の重要性を考えると、MLモデルはユニークな化合物の数が多いADMEデータでトレーニングすることが不可欠です。潜在的な医薬品候補の開発を進めるか否かの判断を迫られる関係者の間でモデルの予測に対する信頼性を高めるには、データサイエンティストはADMEパラメータに必要なレベルの構造多様性を持つデータソースを選択する必要があります。
GOSTARとChEMBLのデータ多様性を比較
予測モデル構築のための最も一般的なデータソースは、GOSTARとChEMBLの2つです。どちらも創薬研究者、計算科学者、薬理学者、毒物学者が創薬・開発プログラムをサポートするために使用しています。GOSTARとChEMBLのデータの品質は製薬業界で高く評価されており、品質基準を維持するために手作業によるキュレーションプロセスが組み込まれています。
しかし、いくつかの大きな違いがあります。GOSTARはChEMBLの化合物、怪物活性、文献資産、特許の数を大幅に上回っています(表1)。*3
| Database | Compounds | Bioactivities | Scientific literature | Patents |
|---|---|---|---|---|
| GOSTAR | 9.4 million | 32 million | 208,901 |
90,614 |
| ChEMBL | 2.4 million | 20 million | 83,415 | 2,564 |
表1:GOSTARとChEMBLのデータベースサイズの比較
しかし、量的な優位性は、多様性で対応しなければ意味がありません。この重要な点で、GOSTARデータはChEMBLデータとどのように対照をなしているのでしょうか。
KNIMEを用いた化合物カバレッジの決定
GOSTARとChEMBL化合物セットの分子類似性を比較するために、Konstantz Information Miner(KNIME)を使用しました。KNIMEは、機械学習やデータマイニングモデルを構築するためのツールやワークフローを備えたオープンソースのデータ分析、レポート、統合プラットフォームです。*4
ADMEパラメータを幅広く選択し、GOSTARとChEMBLから検索結果を収集しました。
KNIMEにファイルをアップロードして解析し、Molecule Type Castノードで文字列をSMILES(simplified molecular input line entry system)に変換しました。次に、RDKit Fingerprint nodeを使用して、円形半径が2のハッシュ化された1024ビットのMorganフィンガープリントを生成しました。これは、分子類似性を検索する際に、ビット長や半径の大きいほかのフィンガープリントよりも高速で同等の結果をもたらすことが文献で示されています。*5 Chemistry Development Kit(CDK)のフィンガープリント類似度ノードを用いて、2つのテーブルの谷本類似度係数を算出しました。最後に、Joinerノードを用いてノードの結果を結合し、ヒストグラムノードを用いて結果を可視化しました(図1)。
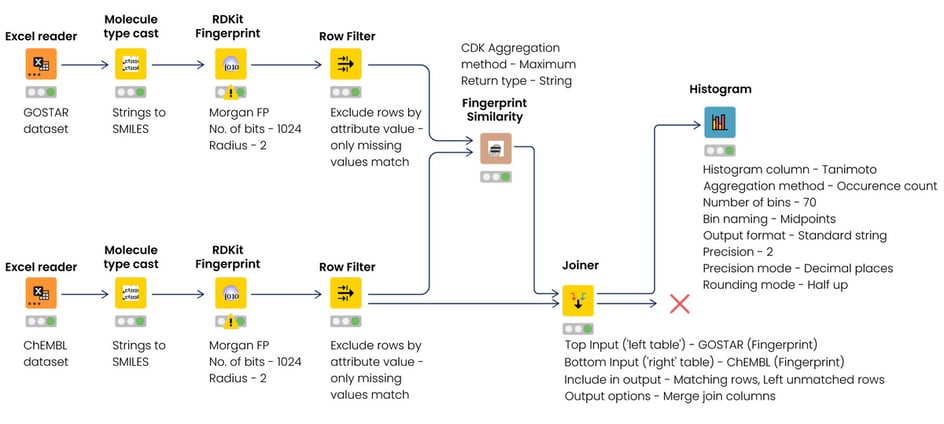
GOSTARのデータ優位性の確立
オーバーラップ解析の結果は明らかです。GOSTARに含まれるユニークな化合物の数は、ChEMBLデータベースと重複する化合物の2倍から7倍です(表2)。
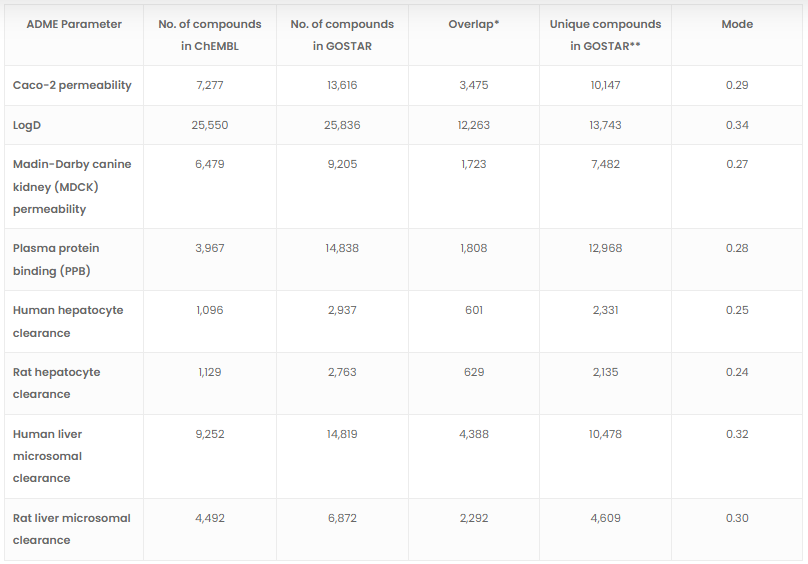
*Overlap=ChEMBLとGOSTARのフィンガープリント類似度が1の化合物の数
**GOSTARのユニークな化合物=<0.98谷本類似性

このテストにより、GOSTARはChEMBLよりもADMEパラメータの例証となるユニークな化学構造を多く含んでいることが間違いなく立証されました。GOSTARが多様性において明らかに優位であることの意味は深いです。予測モデルの精度を高めたいデータサイエンティストや計算科学者は、ChEMBLよりもGOSTARのADMEデータを利用したほうがよいでしょう。
GOSTARのデータは、MLモデルの予測精度を向上させます。
MLモデルの学習に使用されるデータにおける構造の多様性は、その予測精度を示す重要な指標の1つです。そのため、データソースを選択する際には、ユニークな化合物の数を主要な考慮事項とすることが不可欠です。
オーバーラップ解析の結果、GOSTARデータはChEMBLデータと比較して明らかに有効であることが判明しました。GOSTARは、より大規模なデータベースと、手動でキュレーションされたコンテンツの質から、予測モデリングを用いた創薬・開発プログラムにおいて、明らかに優れたデータソースであることがわかります。
GOSTARは、次の大きなブレークスルーを求めるグローバルな製薬会社やバイオテクノロジー企業に、包括的で信頼性の高い高品質のデータを提供しています。GOSTARがお客様の目的達成にどのように貢献できるのか、ぜひお聞かせください。
*1:Kennedy, T. (1997, October). Managing the drug discovery/development interface. Drug Discovery Today, 2(10), 436–444. https://doi.org/10.1016/s1359-6446(97)01099-4
*2:DiMasi, J. A. (1995, July). Success rates for new drugs entering clinical testing in the United States. Clinical Pharmacology & Therapeutics, 58(1), 1–14. https://doi.org/10.1016/0009-9236(95)90066-7
*3:ChEMBL Database. Retrieved March 3, 2023, from ChEMBL website: http://www.ebi.ac.uk/chembl/
*4:KNIME: Open for innovation. Retrieved February 22, 2023, from KNIME website: https://www.knime.com/
*5:Landrum, G. (n.d.). RDKit 2012 UGM. Retrieved 6 March 2023, from Rdkit.org website: https://www.rdkit.org/UGM/2012/

|
Excelra GOSTAR|SARデータベース最新のSARデータを収集、整理し、最新に維持するのに、あなたの時間を割く必要はありません。 GOSTARを使うだけで、最新の整理されたSAR情報が入手でき、研究に集中できます。AIモデルを構築するのに、データを集めたり整理したりする必要はありません。Excelraが専門化チームによるマニュアルキュレーションで構築されたGOSTARは、化学構造と生物学的、薬理学的、治療学的活性を結びつけることで、数百万の化合物の360度ビューを提供します |







