Ákos Tarcsay, Calculators製品マネージャー,
Wendy Warr氏(Wendy Warr & Associates Home Page)による、2022年Chemaxonユーザー会レポートより
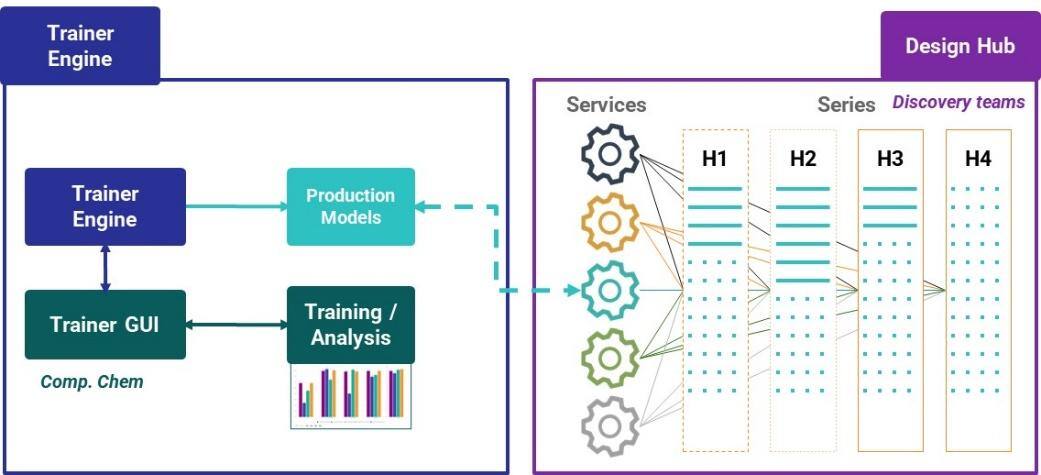
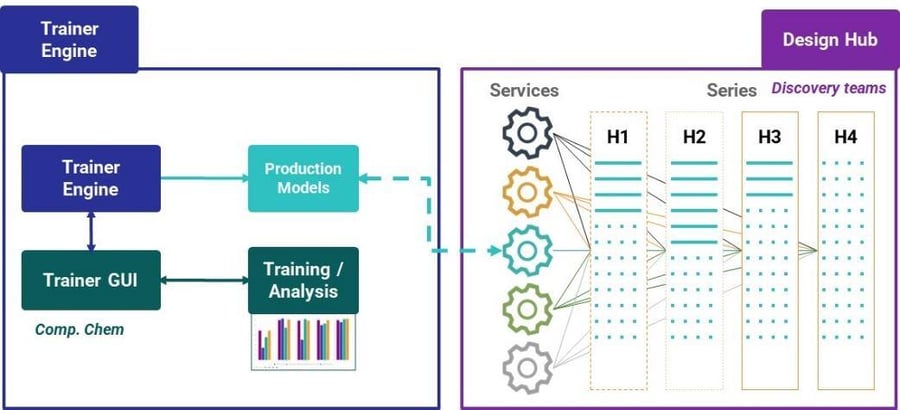
機械学習(ML)のライフサイクルは、データの収集、標準化、トレーニング、可視化、トリアージを含む実験、モデルの展開と再トレーニングを経て行われます。Chemaxonは、データの取り込みから前処理、モデリング、レビュー、予測までをサポートするプロセスを開発しました。Ákosは、Java MLライブラリ、統計的機械知能および学習エンジン(SMILE)を含むインフラストラクチャー(図3)の構築について説明しました。
Chemaxonの標準化には、塩、溶媒和合物、および異性体の処理が含まれており、他の手法よりも優れているとされています。*1Ákosは、Chemaxonの異性体アルゴリズムを低分子保持時間(SMRT)*2データセットに適用し、1つの異性体の場合にランダムに選択された7,000件のトレーニング事例を用いて、252件の異性化が影響した15,000の化合物のテストセットで、異性体の有無で実行された場合の非常に満足のいく結果(R2 = 0.9)を報告しました。
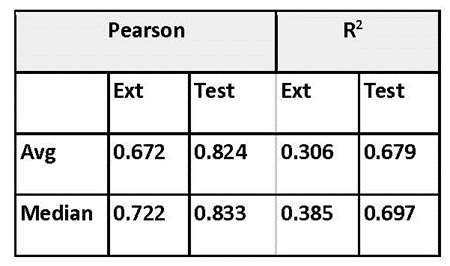
彼は、ChEMBLデータセットから163のChEMBLターゲットの活性を使用して予測力を探求しました。*3データセットは、テストセットとトレーニングセットに10:90の比率で分割され(総トレーニングサイズ160,000、総テストサイズ18,000)、最近の文書年から30ポイントが外部セットに予約されました。外部セットは特に難しかったです。最良のモデルの予測力は、表1にまとめられています。
Ákosは、conformal predictionを使用して信頼度を調べました。*4 17,661件のうち、14,233件のテストセットに対して、予測の80.6%が誤差範囲内にあり、4,890件のうち3,344件の外部セットでは、68.4%が誤差範囲内にありました。SAMPL7では、ChemaxonのChemicalizeツールキットがマクロ規模のpKa予測を行うための経験的な参照方法としてテストされ、他の方法よりも優れた結果を出しました。
次に、Ákosは、MoleculeNetデータセットに基づく血液脳関門透過性分類のユースケースを示しました。*5生成されたランダムフォレストモデルは、物理化学特性および構造記述子を捉えた43の記述子を使用し、高いマシューズ相関係数(MCC = 0.6)と0.95の感度を示しました。
もう一つのユースケースは、PubChem BioAssayデータセットを使用したPAMPA透過性です。Ákosは、分子量が800未満で透過性が100のカットオフを使用する“Phenotype”フィールドを選択して、2029件の事例を標準化しました。646件を低/中、1383件を高と分類しました。MACCSキーに基づくtSNEプロットを作成し、2つのクラスターを作成しました。クラスター1でトレーニングし、クラスター2で予測を行いました。ベースモデルはメッセージパッシングニューラルネットワークで、トレーニングセットでは受け入れ可能な精度(MCC = 0.39)を示しましたが、テストケースでは低い性能(MCC = 0.07)でした。Trainer Engineを使用して生成されたGradient Tree Boostアンサンブルモデルは、19の記述子を使用して、対応するテストセットで有望な精度(MCC = 0.41)を示しました。
モデルは、化学シリーズ、データ、予測、および化学プロジェクト管理を接続するChemaxonのディスカバリーハブであるDesign Hubで利用可能になります(図4)。Design Hubはサービスに対して対応可能です。「production(本番運用)」フラグを設定するだけで、モデルはすぐにユーザーに利用可能になります。
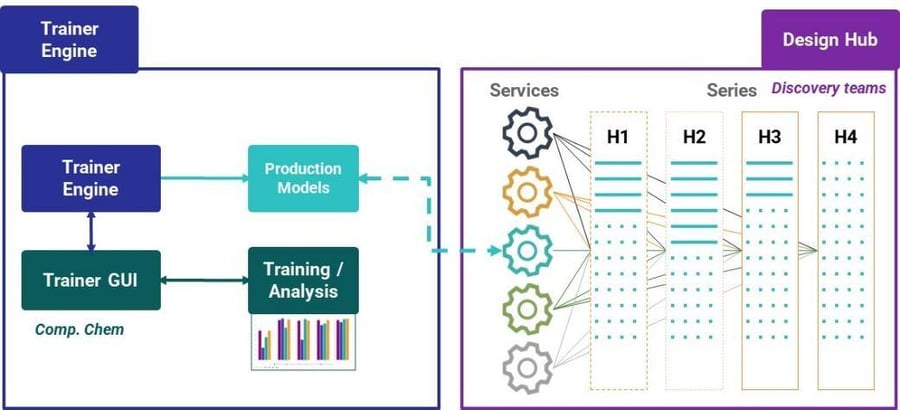
Trainer Engineは、データを信頼できるモデルに翻訳し、モデル管理を集約します。Design Hubは、プロジェクトチームメンバーやリソースを接続し、ディスカバリーを追跡および管理します。
*1:Dolciami, D.; Villasclaras-Fernandez, E.; Kannas, C.; Meniconi, M.; Al-Lazikani, B.; Antolin, A. A. canSAR chemistry registration and standardization pipeline. J. Cheminf. 2022, 14 (1), 28.
*2:Domingo-Almenara, X.; Guijas, C.; Billings, E.; Montenegro-Burke, J. R.; Uritboonthai, W.; Aisporna, A. E.; Chen, E.; Benton, H. P.; Siuzdak, G. The METLIN small molecule dataset for machine learning-based retention time prediction. Nat. Commun. 2019, 10, 5811.
*3:Lenselink, E. B.; ten Dijke, N.; Bongers, B.; Papadatos, G.; van Vlijmen, H. W. T.; Kowalczyk, W.; Ijzerman, A. P.; van Westen, G. J. P. Beyond the hype: deep neural networks outperform established methods using a ChEMBL bioactivity benchmark set. J. Cheminf. 2017, 9, 45.
*4:Norinder, U.; Carlsson, L.; Boyer, S.; Eklund, M. Introducing conformal prediction in predictive modeling. A transparent and flexible alternative to applicability domain determination. J. Chem. Inf. Model. 2014, 54 (6), 1596-1603.
*5:Wu, Z.; Ramsundar, B.; Feinberg, E. N.; Gomes, J.; Geniesse, C.; Pappu, A. S.; Leswing, K.; Pande, V. MoleculeNet: a benchmark for molecular machine learning. Chem. Sci. 2018, 9 (2), 513-530.







