創薬の各段階で機械学習モデルを活用することにより、より迅速かつ洞察に満ちたデータ主導型の意思決定が可能になります。 モデル生成時には、データセットに対して利用可能な全ての記述子が生成されるのが一般的ですが、これらの記述子の重要性は最初からは明らかでないことがあります。 得られた学習済みモデルは、新規化合物の設計や既存化合物の最適化に有用な特性を予測するために使用されます。 計算化学者やケムインフォマティクスの専門家は、通常、これらの記述子のフルセットに基づいて多数のモデルを生成し、その後、望ましい化合物の特性を最も正確かつ頑健に予測できるモデルを選択します。
モデル構築における課題
業界では、ユーザーのニーズとデータタイプに基づいて様々なアルゴリズムが提供されていますが、多くのユーザーは優れたユーザーインターフェース(UI)の不足に苦しんでいます。一部のユーザーはコードレベルで作業を行うのに苦労しており、一方で信頼性の高い管理・バージョン管理ツールが必要とされています。これらのモデルに手動で名前を付けることは多くのアプリケーションでは非実用的です。
Trainer Engineを使用した容易なモデル生成
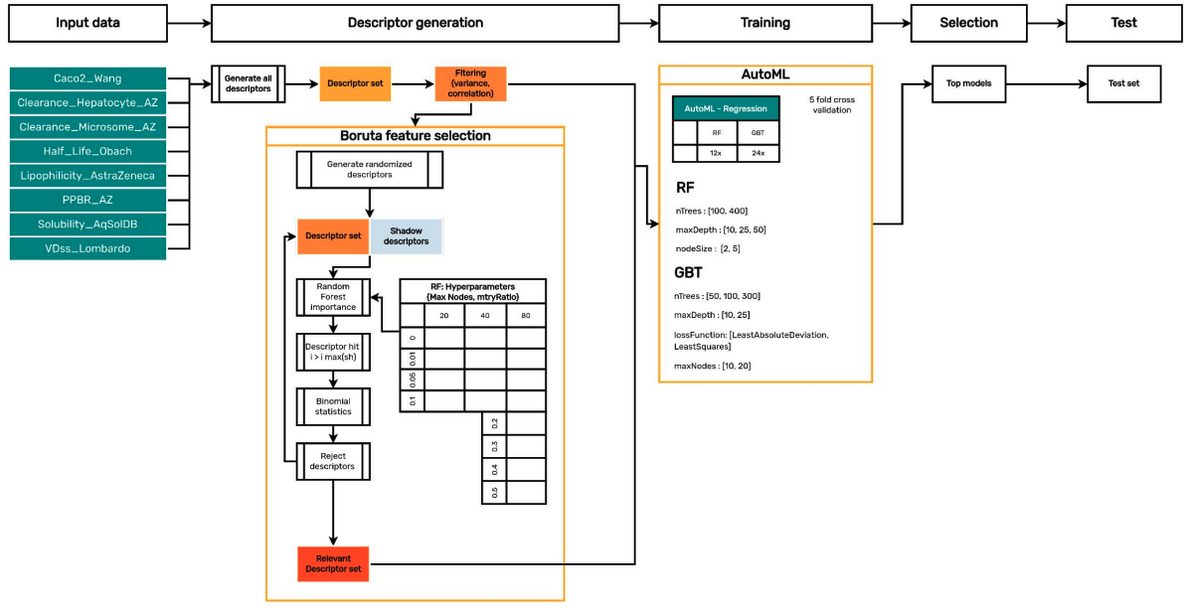
ChemaxonのTrainer Engineは、上記のワークフローをサポートし、ユーザーフレンドリーで使いやすいインターフェースを提供しています。 Trainer Engine内には「Automated Model Building」(AutoML)と呼ばれるワークフローがあり、経験が少ない研究者でも、あるいは未経験の研究者でも、様々なモデル(ランダムフォレスト、勾配ブースト木など)を簡単に生成できます。 このモデル構築機能はわずかな手動入力を必要とし、以下のステップで要約されます:
-
ユーザーは低分子データセット、予測する観測値、回帰か分類かを選択し、実行を開始します。
-
データセット内の化合物構造がチェックされ、標準化されます。
-
利用可能な全ての記述子(約2500:独自のChemaxon記述子とOpenSource記述子の組み合わせ)が生成されます。
-
Borutaアルゴリズム[1]が記述子のセットを最も関連性の高い記述子のサブセットに縮小します。
-
AutoML機能が同じデータセットに対して、異なるハイパーパラメータを使用して様々なモデルを学習します。
-
ユーザーは分析ページを通じて生成されたモデルを分析し、モデルのパラメータを改良して再実行するか、または最適なモデルを選択して実運用に導入します。

時間とリソースの効率
Borutaアルゴリズムを利用して大規模な記述子セットから最も重要な特徴を選び出すことで、モデラーは必要最小限の記述子を用いて効果的なモデルを構築することが可能となり、計算コストの削減とオーバーフィッティングのリスク低減が実現します(具体的な分析結果については、添付された画像をご参照ください):ここでは、Therapeutics Data Commonsから提供されるADMET関連ターゲットデータと、ランダムに選ばれた30個のChEMBLベンチマークデータセットを用い、これにBorutaアルゴリズムを適用し、適切な制約条件を設けた上でTrainer Engineによって選出されたデータセットを比較分析しています。 Borutaを利用した特徴選択とハイパーパラメータの調整に関する性能評価は、「Building machine learning models using relevant features」というポスターセッションで後日発表されました。 これらの高品質なモデルは、関連性の高い特徴セットと事前に選定されたハイパーパラメータ(mTryRatio、maxnodes等)を定義することにより、優れた性能を発揮します。 ハイパーパラメータ選択の詳細については、ポスターセッションのリンクをご参照ください。
最適な手法の選定
Trainer Engineの「Analyze」ページでは、モデルの詳細情報や精度の測定結果を視覚化し、比較・評価するためのフレキシブルでカスタマイズ可能なビューが提供されています。 この機能により、モデラーは与えられたデータセットに対して最も効果的な手法(例えば、ランダムフォレストや勾配ブースティング木)を見極めることができ、ユーザーはこれらの手法と組み合わせてハイパーパラメータを適切に微調整する方法を理解することが可能となります。 最適なモデルが決定されれば、それをスムーズに本番環境に導入することができます。

Design HUBとの統合
Design HUBとTrainer Engineの統合は、この機能の有効性を示す優れた例となっています。Design HUBで生成された仮想化合物は、プラグイン形式でTrainer Engineの機械学習モデルを利用した特性計算にアクセスでき、選定したモデルへのアクセスはTrainer Engine内でデプロイを通じて管理することができます。これにより、ユーザーは任意の特性において最も精度が高く堅牢なモデルを利用できるようになります。
将来展望
Chemaxonは、創薬分野での機械学習研究の要求に応えるため、Trainer EngineをDeepChemのようなディープラーニングフレームワークでさらに強化する予定です。 私たちの目標は、最新の技術スタックとユーザーフレンドリーなインターフェースを提供し、低分子の計算空間を活用することで、機械学習の初心者から専門家まで、全てのユーザーのニーズに応え続けることです。
[1] Kursa MB, Jankowski A, Rudnicki WR, Boruta—a system for feature selection. Fundam. Inform. 2010; 101(4):271–285. doi: 10.3233/FI-2010-288
Posted by Chemaxon on 26 10 2023
関連製品
 |
ChemAxon Design Hub 創薬プロジェクトのDX基盤革新的な創薬プロジェクトのデジタルプラットフォーム Design Hubは、「仮説駆動型」および「データ駆動型」アプローチを統合し、創薬の早期段階におけるDMTA(Design, Make, Test, Analyze)サイクルを効率化するための画期的な情報プラットフォームです。コンテンツハブとしての機能も備え、創薬プロセス全体の効率化と成功率向上を実現します。さらに、社外のCROや大学とのコラボレーションを円滑に進めるためのセキュアな情報共有機能を提供し、プロジェクトタスクの効率的な推進をサポートします。 |




